STEP01. Import Data
import pandas as pd
red_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv"
white_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv"
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')pinkwink github의 red_wine / white_wine 데이터로 프로젝트를 진행한다.
해당 파일을 훑어보니 ;로 데이터가 나뉘어져있어 separate는 ;자로 하였다.
STEP02. Arrange Data
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine.info()red와 white를 1, 0으로 지정하고 둘을 합쳐 wine파일을 만들어 주었다. info를 확인해보니 잘 합쳐진것을 볼 수 있다.
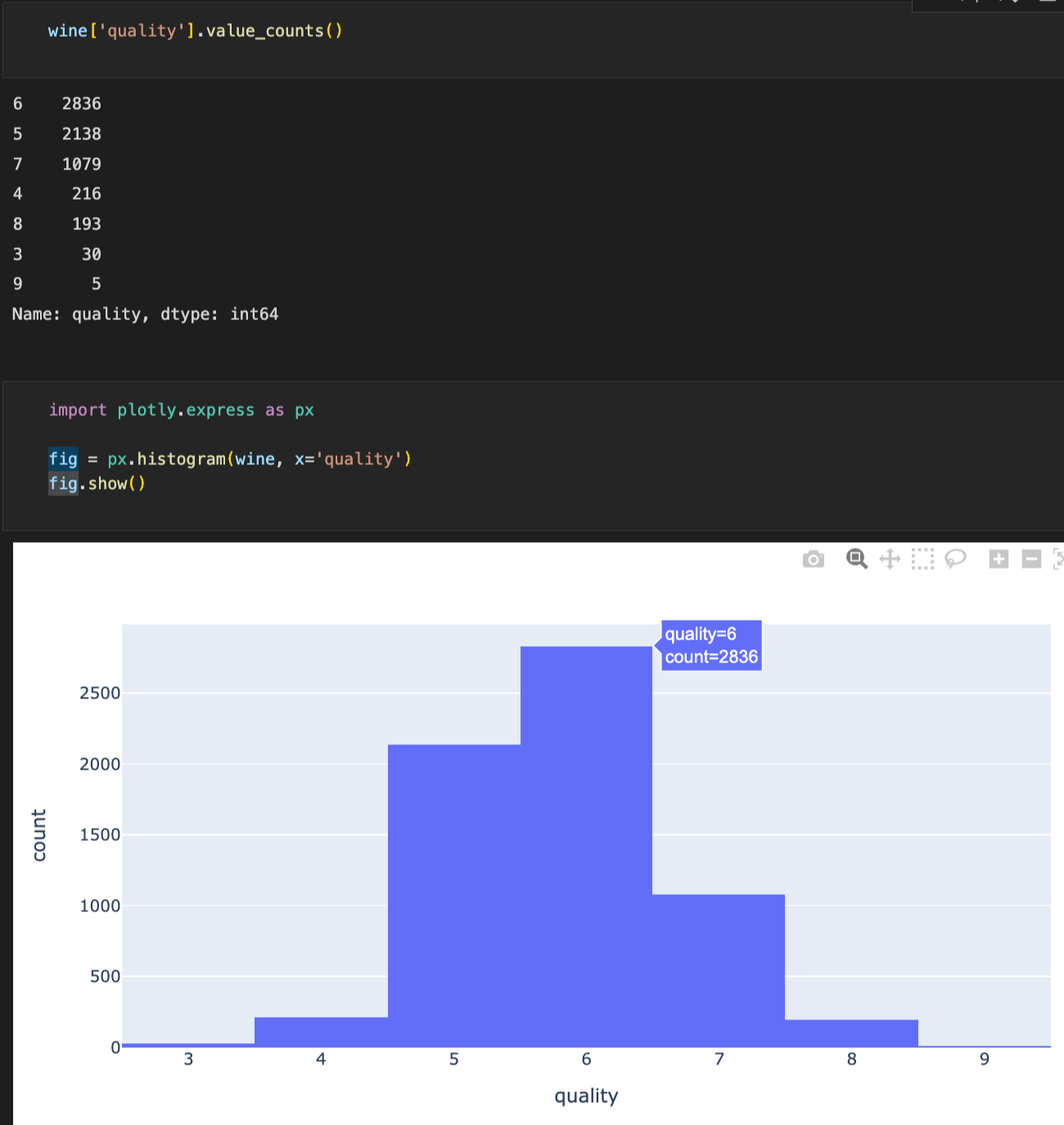
value_count로 'quality' 칼럼 항목의 퀄리티별 갯수를 확인한다.
histogram으로 도표로 나타냄과 동시에 count를 볼 수 있게 한다
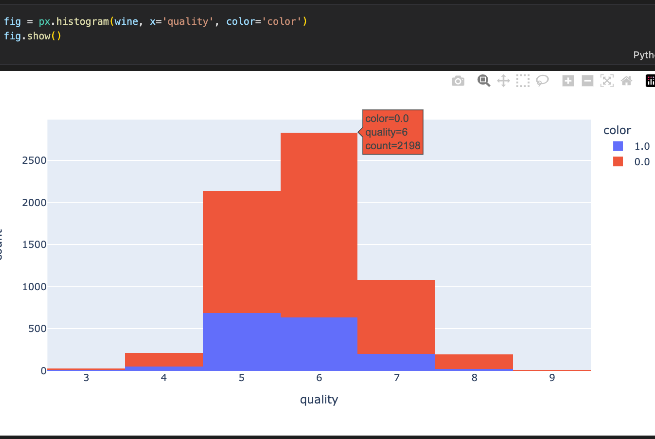
color에 red와 white를 구분지어줬던 color 컬럼을 넣어 화이트와 레드의 비중 또한 나타내었다.
STEP03. Classify Red & White
X = wine.drop(['color'], axis=1) #color column 빠진 나머지
y = wine['color']
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
np.unique(y_train, return_counts=True)X에 red와 white가 분리되어있는 color 칼럼을 drop한 나머지 데이터를 할당 , y에 color값(지도학습을 위한 label)만 할당해준다.
train데이터와 test데이터로 분리해준다.np.unique()로 값들이 제대로 들어갔는지 확인했다.

plotly.graph_objects import 하여 train데이터와 test데이터가 어느정도의 비율로 들어갔는지 도표로 확인한다.
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)결정나무 import해주고 fit학습시킨다.
from sklearn.metrics import accuracy_score
#train accuracy
y_pred_tr = wine_tree.predict(X_train)
#test accuracy
y_pred_test = wine_tree.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr)) #y_train값과 y_pred_tr간의 정확도
print('Test Acc : ', accuracy_score(y_test, y_pred_test))train과 test data의 accuracy를 확인해준다. 95.5%와 95.6%로 상당히 유사했다. 과적합은 일어나지 않았다.
STEP04. Data Preprocess
: 전처리라는건, 기본적으로 바로 아래의 표와 같이 생긴 데이터들을 어떤 scaler을 통해 바꾸는 것이 좋은지 시도해보는 것
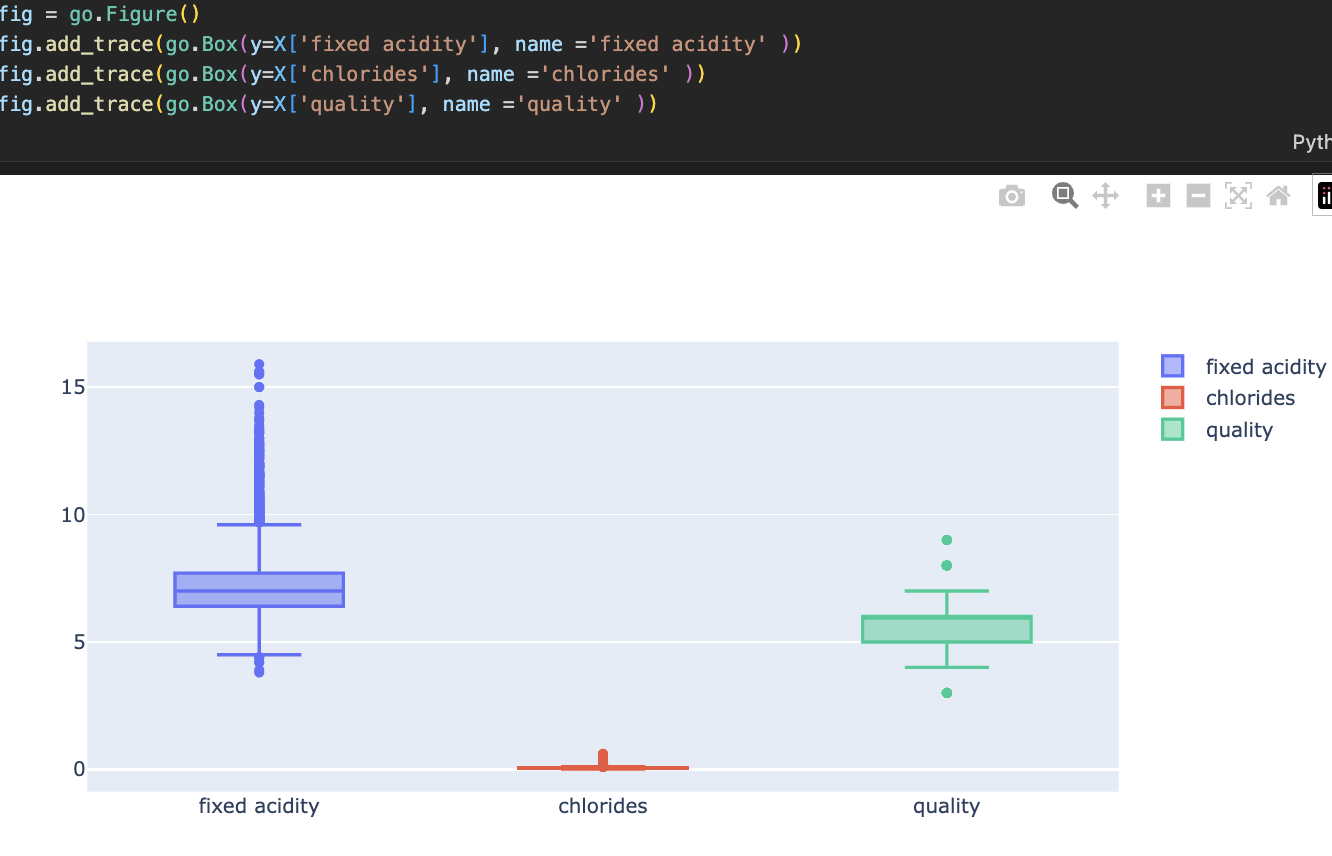
기본적으로 해당 데이터를 box로 먼저 확인해보았다.
일반적으로, 머신러닝에서는 컬럼들간의 feature, 범위의 격차가 심할 경우에 제대로 학습이 안될수도 있다고 본다.
저렇게 생긴 경우 scaler를 적용하는 것은 효과적일수도 있다. *decision Tree의 경우에는 효과 없다.
어느 scaler를 적용했을때에 더 효과적일지는 해봐야 아는 것이다.
- Scaler(MinMax / Standard)
from sklearn.preprocessing import MinMaxScaler, StandardScaler
MMS = MinMaxScaler()
SS = StandardScaler()
SS.fit(X)
MMS.fit(X)
X_ss = SS.transform(X)
X_mms = MMS.transform(X)
X_ss_pd = pd.DataFrame(X_ss, columns=X.columns)
X_mms_pd = pd.DataFrame(X_mms, columns=X.columns)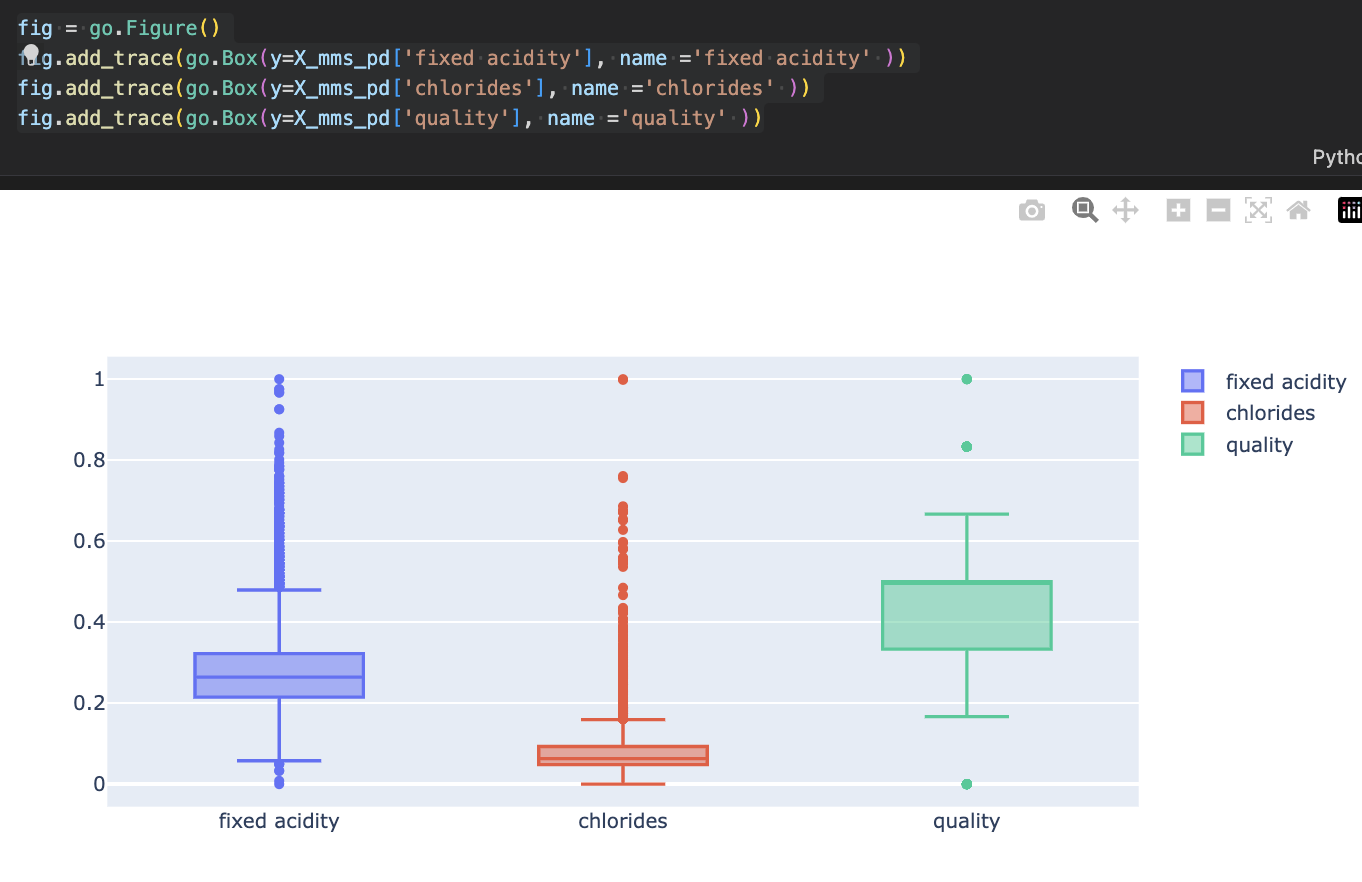

#mms
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))
#ss
X_train, X_test, y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))mms와 ss의 acc는 큰 차이가 나지 않았다.
STEP05. Classify Taste
# 5등급 초과하면 1 아니면 0
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
wine.head()grader가 6이상이면 맛있다는 의미의 1, 아니면 0을 대입한다.
X = wine.drop(['taste'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)taste칼럼을 분리하여 train과 test데이터를 만들고, fit한다.
y_pred_tr = wine_tree.predict(X_train) #train accuracy
y_pred_test = wine_tree.predict(X_test) #test accuracy
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))둘의 정확도를 확인해보니 모두 100%가 나왔다.
100%라는 정확도가 사실 믿기 힘드니 검증을 해본다.
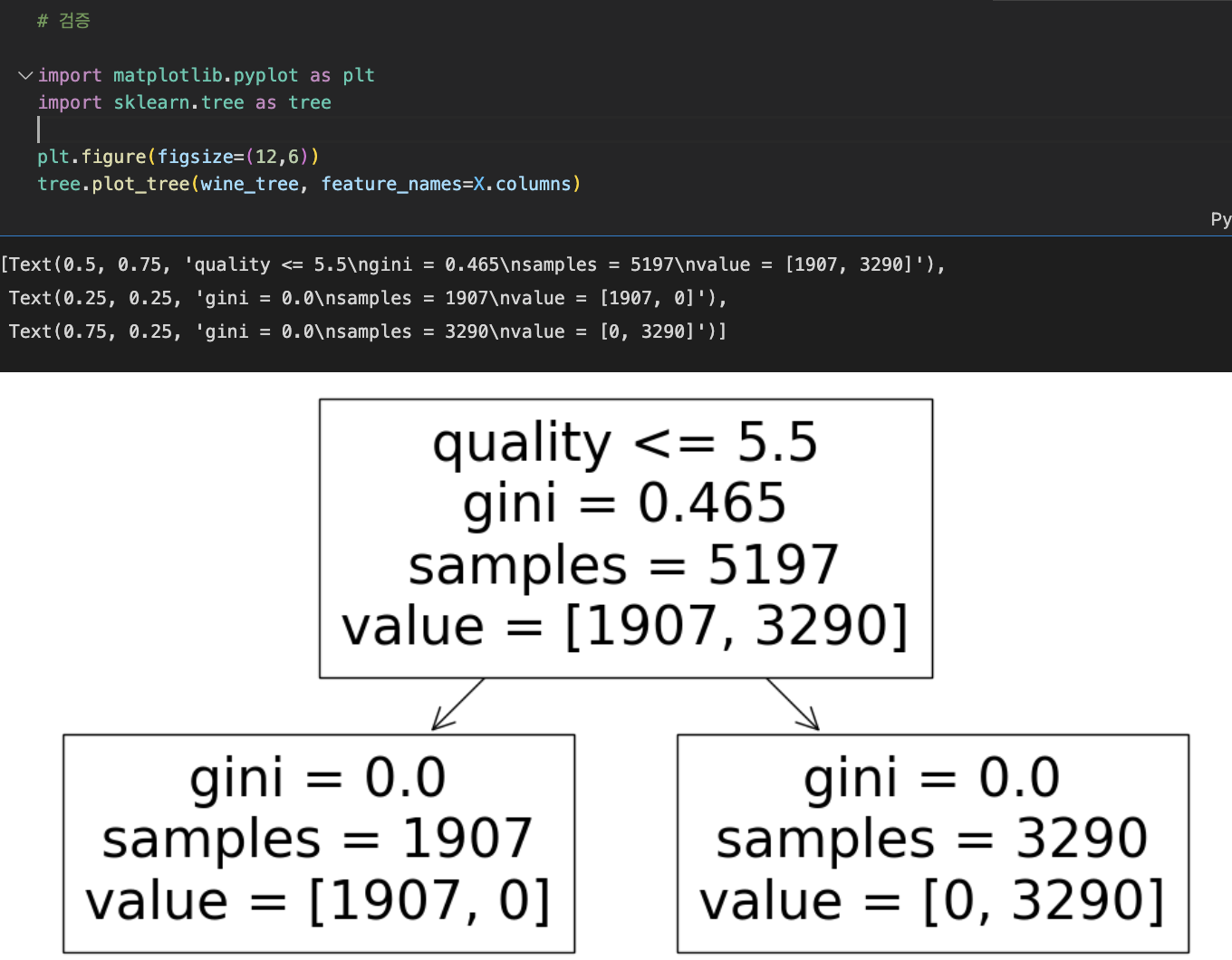
** 이유
X와 y를 학습시키는 과정에서 taste는 지웠지만 taste칼럼의 근간이 되는 quality는 그대로 존재했기 때문에,
decision Tree를 보면 quality를 가지고 학습한 것이 보인다.
-> quality를 없애고 다시 시작해주어야 한다.
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train) #train accuracy
y_pred_test = wine_tree.predict(X_test) #test accuracy
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))
+ which one is better?

'Machine Learning' 카테고리의 다른 글
| [ML] Hyperparameter Tuning_ 교차검증 (0) | 2023.01.05 |
|---|---|
| [ML] Pipeline (0) | 2023.01.05 |
| [ML] Encoder and Scaler (0) | 2023.01.04 |
| [ML] Titanic Survivor Prediction_ dicaprio&winslet (0) | 2023.01.03 |
| [ML] Titanic Survivor Prediction (0) | 2023.01.03 |



