STEP01. Import Data
# !pip install plotly_express
import pandas as pd
titanic_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/titanic.xls"
titanic = pd.read_excel(titanic_url)
titanic.head()민형기 강사님의 github에 있는 titanic.xls를 사용하여 프로젝트를 진행한다.
STEP02. Data Analysis
import matplotlib.pyplot as plt
import seaborn as sns
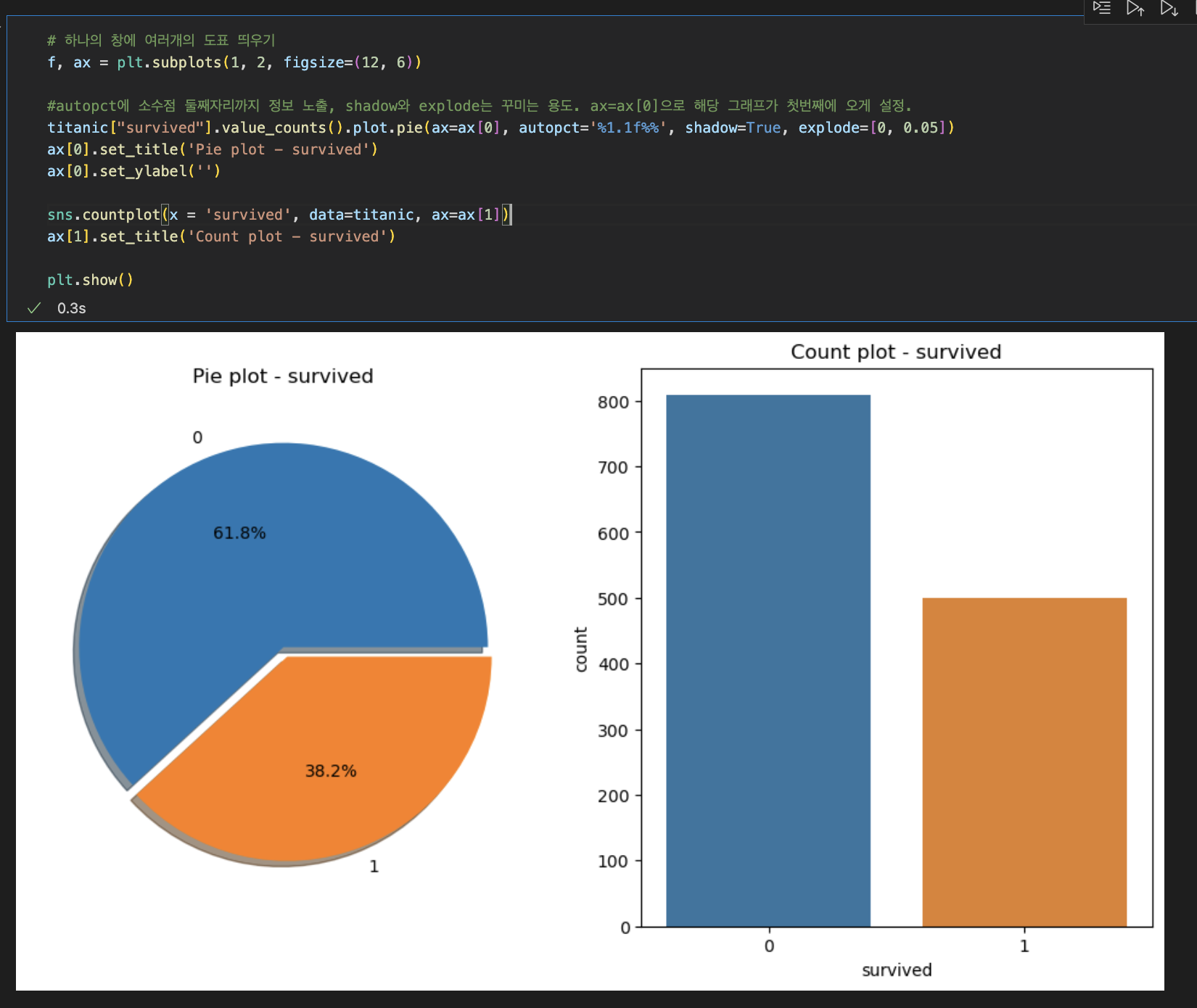
<생존자 분석>
- plt.subplots( )로 하나의 창에 여러개의 도표를 띄우게 하고 이를 f, ax 변수에 담아준다.
- pie표 하나와 countplot표 하나를 만드는데, 각각 다른 옵션값을 부여한다.
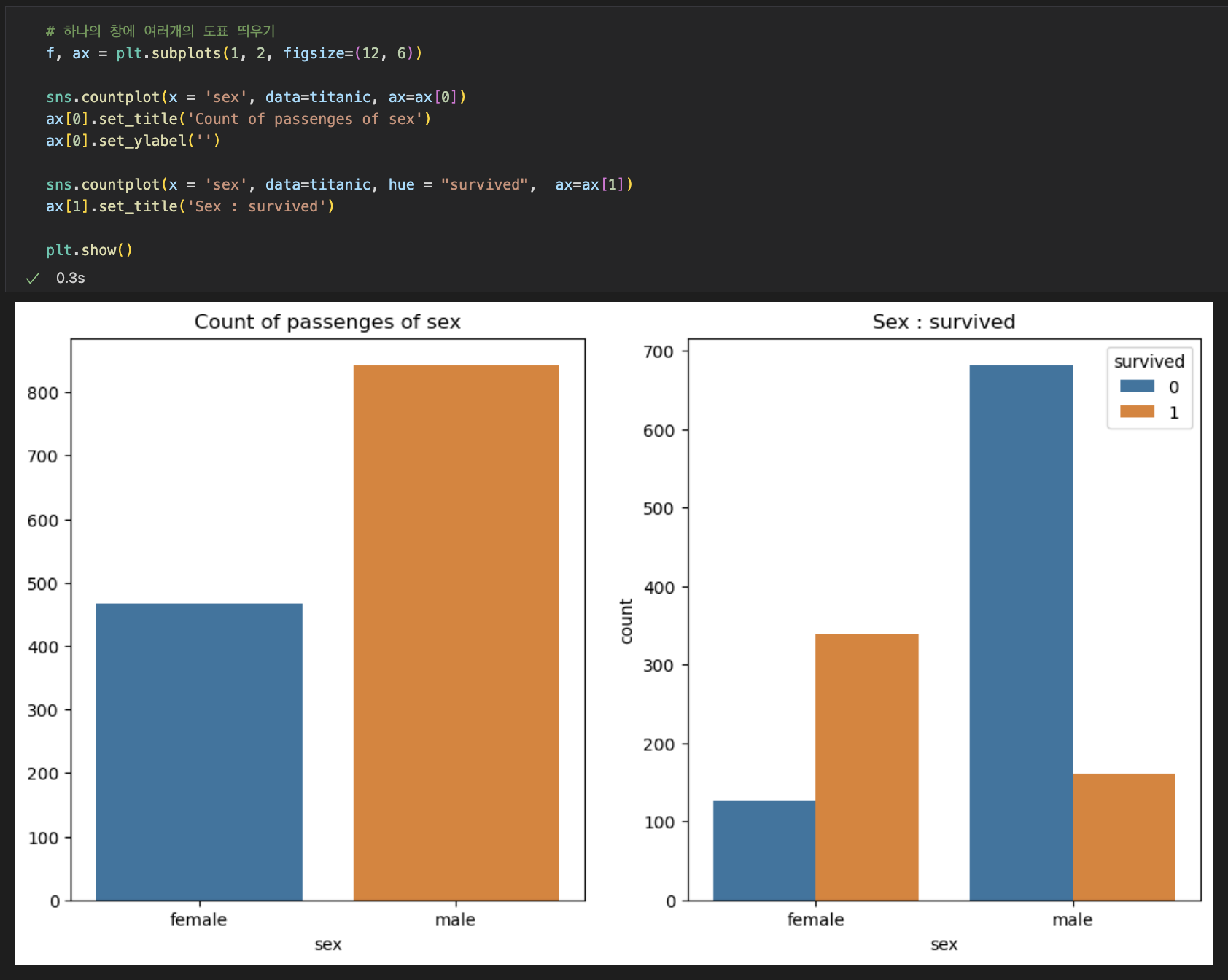
<생존자 성별 분석>
- 위와 같지만, x축을 성별로 지정하여 전체 성별 대비를 보여주고, 오른쪽의 도표에는 hue = "survived"를 지정하여 성별 대비 생존자 수를 나타낸다.
∴탑승인원은 여성이 남성의 반인데, 생존인원은 여성이 남성의 2배 이상에 달하는 것을 볼 수 있다.

<선실 등급 별 생존자 분석>
- crosstab모듈을 사용해 pclass, survived를 넣고 margin=True 옵션으로 전체 합계도 띄워준다.
∴높은 클래스일수록 생존자 비율이 높다는 점을 볼 수 있다.
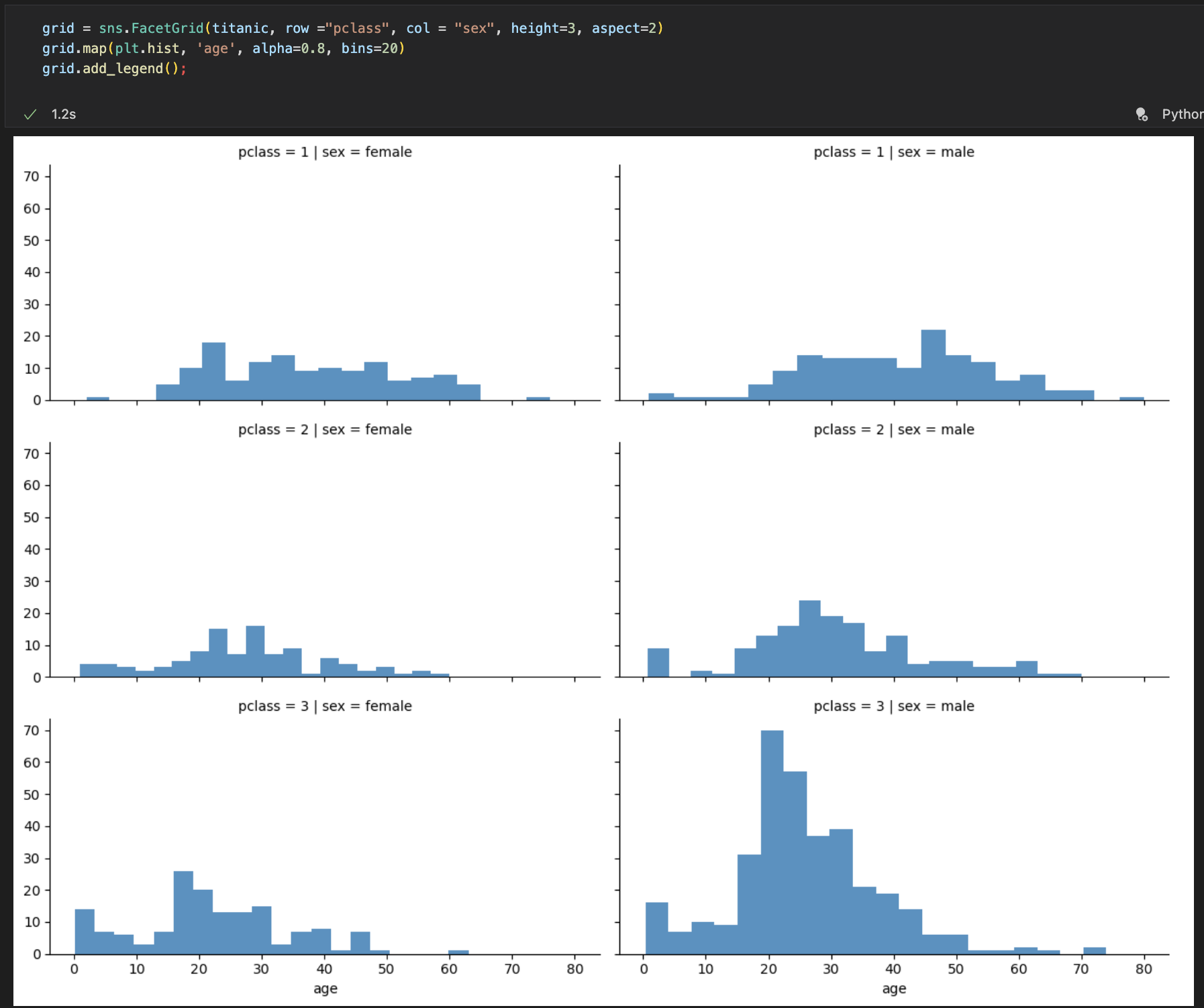
<선실 등급 별 생존자 분석>
- sns.FacetGrid의 형태이다. row를 pclass로 잡아줬기에 class와 sex, age를 기준으로 만들어진 분포도이다.

<나이별 승객 현황>
- plotly.express의 histogram은 커서를 갖다 대면 해당 도표의 정보를 띄워준다.

<선실 등급 별 생존자>
- 확실히 선실 등급이 높으면 생존률이 높은 듯 하다.

<나이를 5단계로 정리>
- cut( ) 명령은 구분지으라는 의미이다. bins=[ ]안의 데이터를 기준으로 구간을 나눠서 labels=[ ]의 이름을 붙인다.
새로운 컬럼으로 해당 내용을 저장해준다.
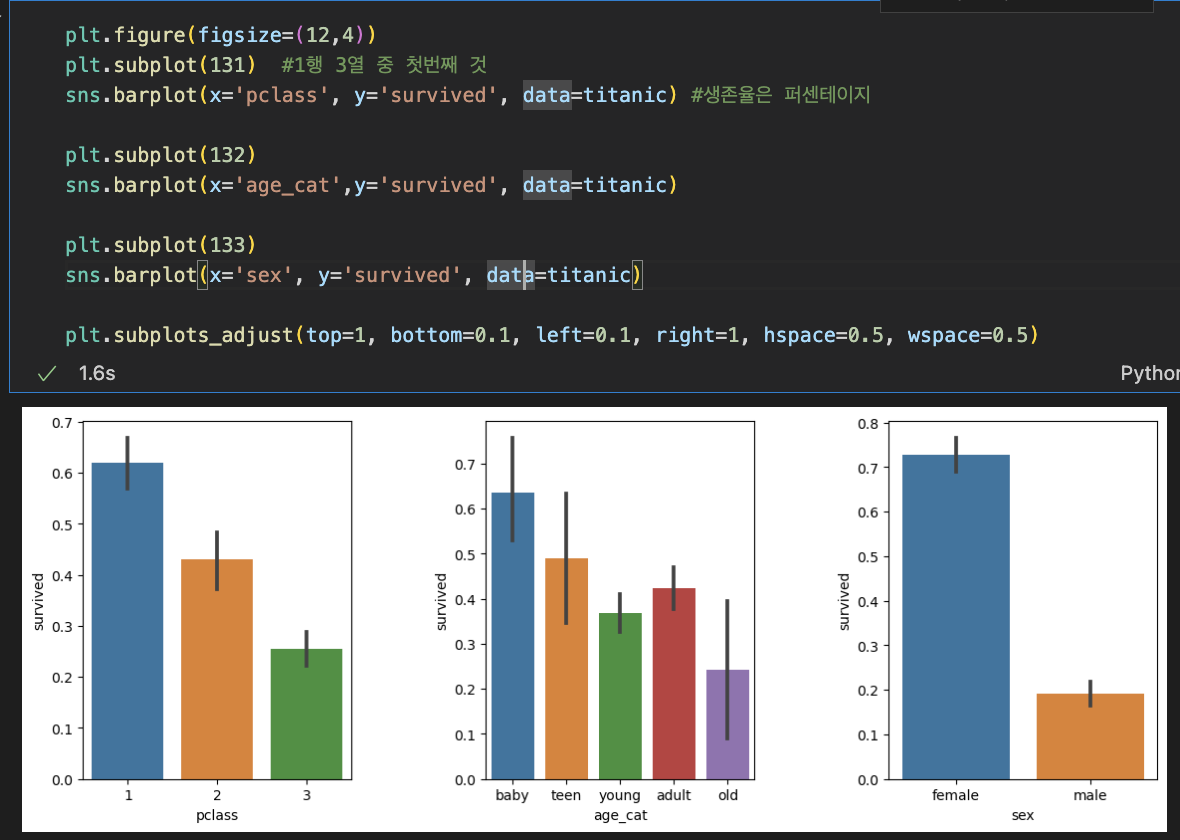
<나이, 성별, 등급별 생존자 수 한번에 파악>
- plt.subplot(131)은 1행 3열 중 첫번째라는 의미이다.
- pclass, age,sex 3개의 barplot을 만들어주었다.
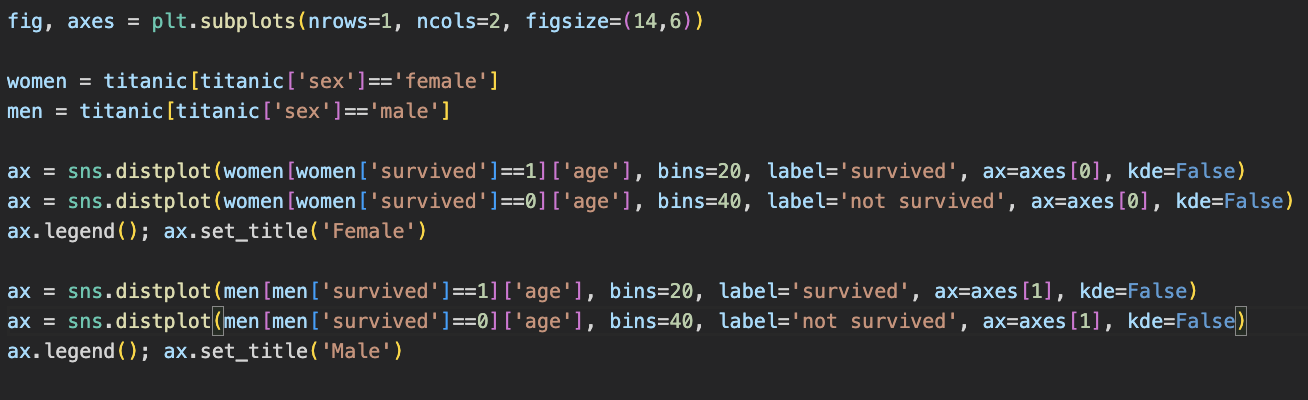

<남/여 나이별 생존 상황>
- fig와 axes로 subplots에서 반환인자를 받아준다. row의 갯수는 하나, column은 2개의 의미이다.
- 여성과 남성의 데이터를 분류해서 빼내온다. 그 중 생존자 1/0을 구분하고 bins로 크기만 구분하여 하나의 표로 그려준다. kde=False를 지정해주지 않으면 라인그래프도 함께 나타난다.
- 주의해야할 점은 bins옵션을 잘게 나눌때 같은 높이가 아니라고 생각해서는 안된다는 점이다. 잘려진 두개의 바가 쌓인 형태를 생각해야 한다는 것이다.

<탑승자 이름에서 신분만 가져오기>
- iterrows( ) 함수를 사용하여 이름 데이터만 tmp변수에 담아 빼온다. 이름 중 신분에 해당되는 파트만 빼오고자 re.search( )를 사용했고 괄호 안의 '\, \s\w+(\s\w)?\.'는 ,로 시작하고 space를 비우며 word가 나오다가 (s\w가 오는데 있을 수도,없을 수도 있다는 점을 ?로 표기해주고 .comma로 끝나는 단어란 것이다. 그 중 뽑아 group하여 title칼럼에 append해준다.
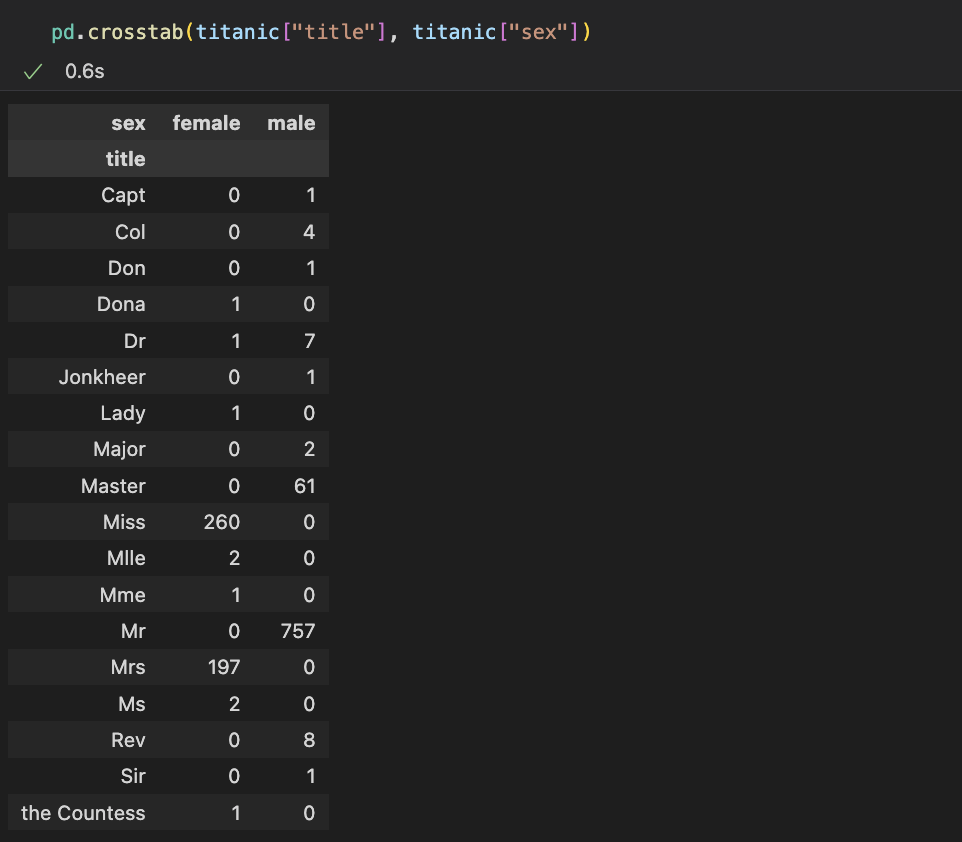
<성별로 본 귀족>
- crosstab( ) 함수를 사용하여 title과 sex를 구분지어 확인해본다. 해당 성씨를 가진 사람 중 남/녀 수를 볼 수 있다.

<사회적 신분 정리>
- Miss나 Mr, Mrs를 제외한 귀족 성씨를 성별을 확인 후 Rare_f / Rare_m으로 구분하였다. 귀족성씨가 아니지만 Miss를 뜻하는 나머지의 성들은 .replace()로 변환해주었다. 이를 title 칼럼에서 확인 가능하게 했다.

<신분,성별 생존률 해석>
- title과 survived column을 title로 groupby( )한다.
- .mean( )은 평균값을 나타내달라는 키워드이다.
- 평민남성 <귀족남성 <평민여성 <귀족여성의 순으로 생존률이 높았음을 확인 가능하다.
'Machine Learning' 카테고리의 다른 글
| [ML] Encoder and Scaler (0) | 2023.01.04 |
|---|---|
| [ML] Titanic Survivor Prediction_ dicaprio&winslet (0) | 2023.01.03 |
| [ML] Data Split_ zip / unpacking (0) | 2023.01.02 |
| [ML] Data split_ tree_ iris (0) | 2023.01.02 |
| [ML] Machine Learning (0) | 2022.12.28 |



