ML의 대표적인 도구 sklearn을 사용할때, 대표적인 두가지(가지를 치자면4가지)의 개념
STEP 01. LabelEncoder
: 문자를 숫자로 바꾸는데 유용하다.


pd.DataFrame으로 표를 하나 생성해준 뒤,
LabelEncoder를 import해준다. 이를 le변수에 담아준 뒤 df['A']를 fit(학습)시켜준다.
le.classes_로 개체를 확인 가능하다.
transform으로 fit에서 학습시킨 부분을 적용시켜주면 된다.
이를 눈으로 확인해보고자 df에 le_A 칼럼을 추가하여 해당 내용을 담아주었다.

fit_transform으로 fit과 transform을 동시 출력도 가능하다.
le.transform(['a'])로 a의 숫자정보를 바로 볼 수도 있다.
inverse_transform으로 숫자에서 문자로 역변환할수도 있다.
STEP 02. Min-Max Scaling

: min이 0이라면 max/x =x'. 분자는 min을 0으로 보낸 것, 분모는 max를 1로 바꾼것을 의미한다.

새로운 dataFrame을 만들고, MinMaxScaler을 import 해온다.
해당 df를 mms에 fit해준다.
다음 mms의 data_max_ / data_min_ / data_range_를 불러오면 df의 최대/최소/길이를 확인 가능하다.
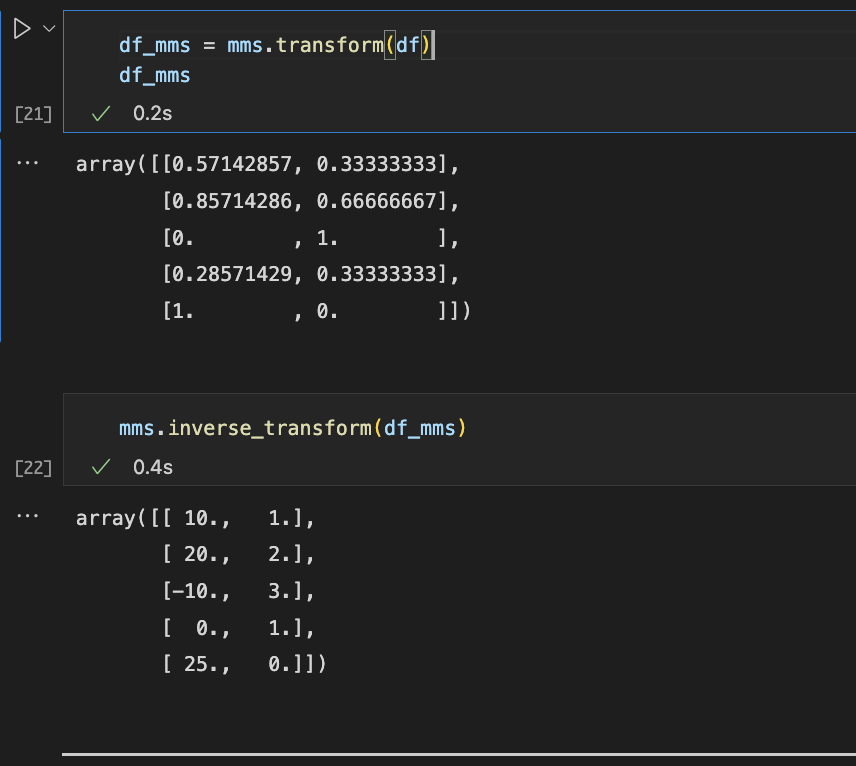
이후 transform 하여 보면 최소값은 0으로, 최대값은 1로 표기되는 것을 볼 수 있다.
역변환은 마찬가지로 inverse_transform해주면 된다.
STEP 03. Standard Scaler
: 표준정규분포와 같은 의미이다.


Standard Scaler를 import해온다.
.mean_ / .scale_로 분모와 분자에 들어갈 평균과 표준편차를 확인한다.
STEP 04. Lobust Scaler

median을 0으로 보는 것이다. (평균이 아니라 제4분위수 중 제2분위수)
Q1은 1로 본다.


새로운 dataFrame을 만들어주는데, 위에서 만든 scaler들과 함께 비교하며 보기 위해 각각을 fit_transform 해준다.

해석에 도움을 주고자 boxplot을 그려봤다.
원본데이터를 보면 5라는 outlier 존재한다. (일부러 준 값)
- minMaxScaler는 min을 0 / max를 1로 준 데이터다.
문제는, 저 5라는 데이터가 노이즈같이 쓸 데 없는 데이터였다면 저 변수 하나때문에 나머지 데이터가 너무 축소된다는 것이다.
- StandardScaler이라고 다르지 않다.
평균과 메디암값의 차이는 매우 작거나 큰 데이터에 대한 영향이 조금 준다는 것이었다.
df의 중앙값을 0으로 가져오다보니 그래프가 왼쪽으로 쏠리게 그려진 것이다.
- RobustScaler는 median이 0이 되고 총 길이를 1로 만든다.
outlier는 그대로 존재하고 이는 그래프의 배치에 큰 영향을 주지 않았다.
'Machine Learning' 카테고리의 다른 글
| [ML] Pipeline (0) | 2023.01.05 |
|---|---|
| [ML] Wine Analysis _DecisionTree (0) | 2023.01.05 |
| [ML] Titanic Survivor Prediction_ dicaprio&winslet (0) | 2023.01.03 |
| [ML] Titanic Survivor Prediction (0) | 2023.01.03 |
| [ML] Data Split_ zip / unpacking (0) | 2023.01.02 |



