STEP01. Import, Split Data
load_iris 데이터를 import 해주고 iris 변수에 담아준다. features 변수에 test용 sample데이터를 2개만 나눠준다.
X_train, X_test, y_train, y_test 4개의 변수를 train_test_split 함수를(sklearn의 데이터를 잘 나눠주는 모델) 사용해서 반환받을 것이다. (train훈련용 한세트, test샘플용 한세트)
test_size를 0.2로 설정하면 훈련용은 80%, 테스트용은 20%로 했다는 것이다.

.shape으로 확인해보면 8:2로 설정해준 비율값에 맞게 120개, 30개가 잘 들어간 것을 볼 수 있다.
STEP02. Check Data
** 데이터 분리시에 주의해야 할 점은, 훈련용 / 테스트용이 잘 분리되어있는지 확인해야 한다는 것이다.
np.unique를 사용하여 확인한다.

각 클래스(setosa, versicolor, verginica)별로 동일 비율이 되면 좋기에 , stritify=labels 옵션을 사용하여 같은 비율로 샘플데이터가 추출되게 해준다. np.unique에서 return_counts=True로 설정하여 해당 값의 갯수를 확인한다. class별 비율을 맞추는건 개인의 선택이지만 꼭 맞춰줘야하는 경우도 생기기에 기억해주자.
STEP03. Making Tree

.fit()은 훈련시킨다는 의미이다. 괄호 안의 X_train은 feature값, y_train은 label값을 의미한다.
max_depth를 2로 설정해주었기에 2번째 가지까지의 treemap이 나타난 것이다.
해석해보자면 setosa는 100% 40개 분류, versicolor는 versicolor40개 중 35개를 맞췄고 verginica1개가 넘어왔고, verginica는 40개 중 39 + versicolor에서 5개가 넘어와 분류된 것을 볼 수 있다.
STEP04. Check Data Accuracy

train 데이터의 정확도는 95.3%인 것을 확인할 수 있다.
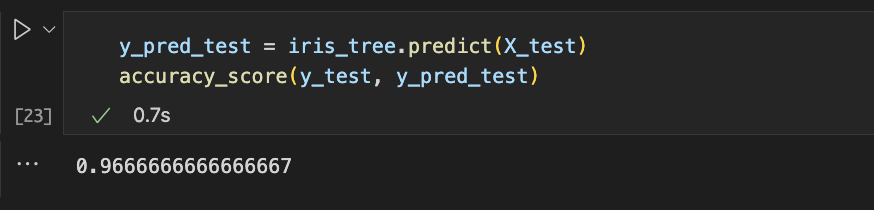
test 데이터의 정확도는 96.6%인 것을 확인할 수 있다.
보통의 경우에는 train데이터보다 test데이터의 정확도가 낮다.
train데이터가 95.3%으로 test데이터의 accuracy값의 근처에 있으니 과적합은 일어나지 않았다는 점을 시사한다.
-> 누군가가 너의 그 모델이 과적합이 일어나지 않는다고 확신할 수 있어? 라고 묻는다면,
01. 확신이 안간다면 데이터를 더 달라 or 더 모을 시간을 달라.
02. 내가 가진 데이터를 8:2로 나누어 봤더니 확인할 수 있었다.
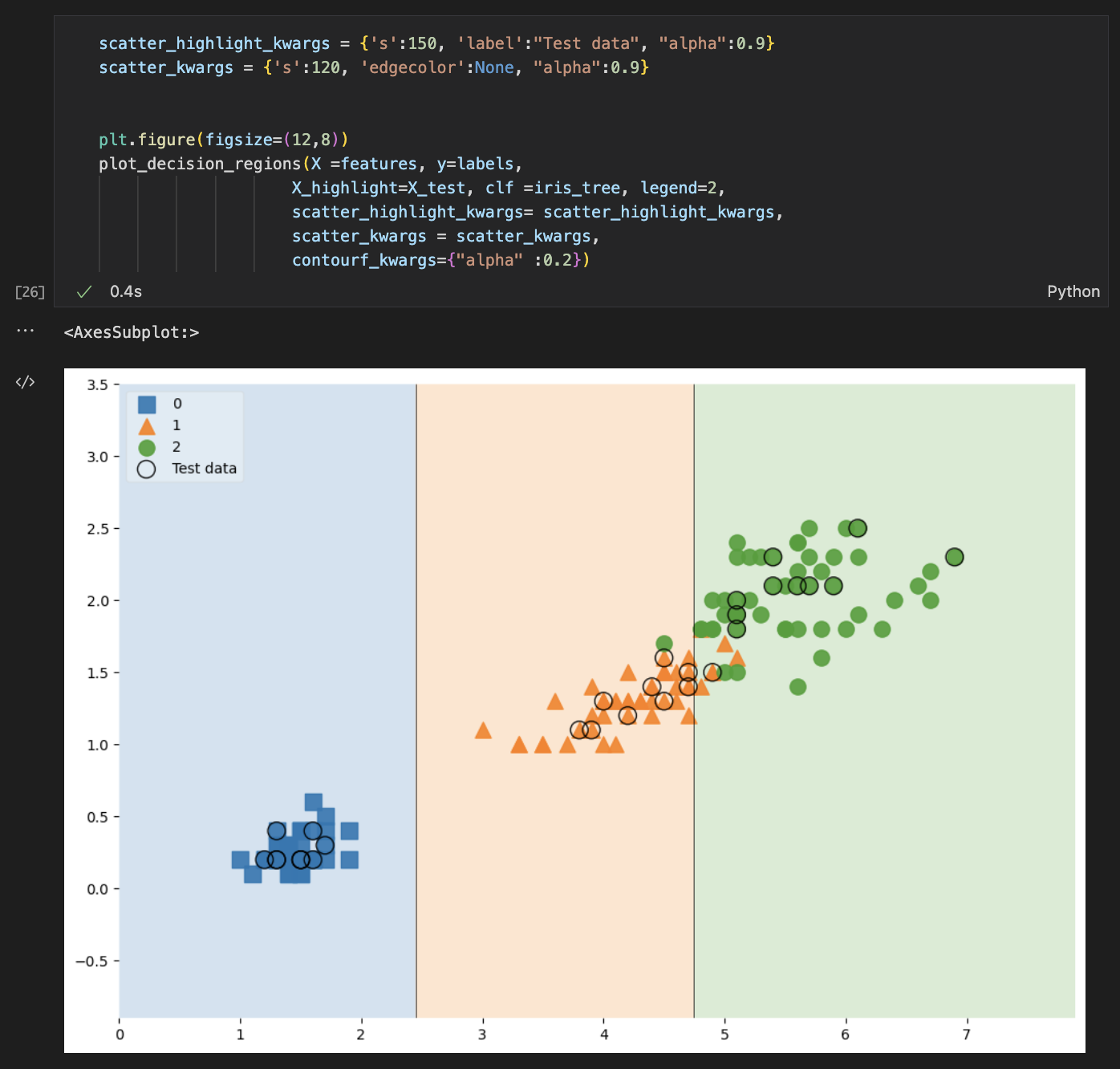
STEP05. Check Data Decision_regions

과적합을 막기위해 max_depth를 한정하는 것이 중요하다.
+ 잔기술을 부려보자면 ..
scatter변수를 하나 만들어본다. 150개 데이터 전체를 표기하고, train데이터와 test데이터를 분리해서 표시하고, 결정경계까지 넣어줘서 그림을 그리게 속성값을 준다.
'Machine Learning' 카테고리의 다른 글
| [ML] Titanic Survivor Prediction (0) | 2023.01.03 |
|---|---|
| [ML] Data Split_ zip / unpacking (0) | 2023.01.02 |
| [ML] Machine Learning (0) | 2022.12.28 |
| [ML] Scikit Learn (0) | 2022.12.28 |
| [ML] Decision Tree (0) | 2022.12.28 |

