
- 오토인코더는 입력과 출력이 동일하다.(자기 자신을 재생성하는 네트워크이다)
- Latent Vector : 잠재변수(가운데 부분), Encoder : 입력쪽, Decoder : 출력쪽
- 인코더는 일종의 특징추출기와 같은 역할을 한다.
- 디코더는 압축된 데이터를 다시 복원하는 역할을 한다.



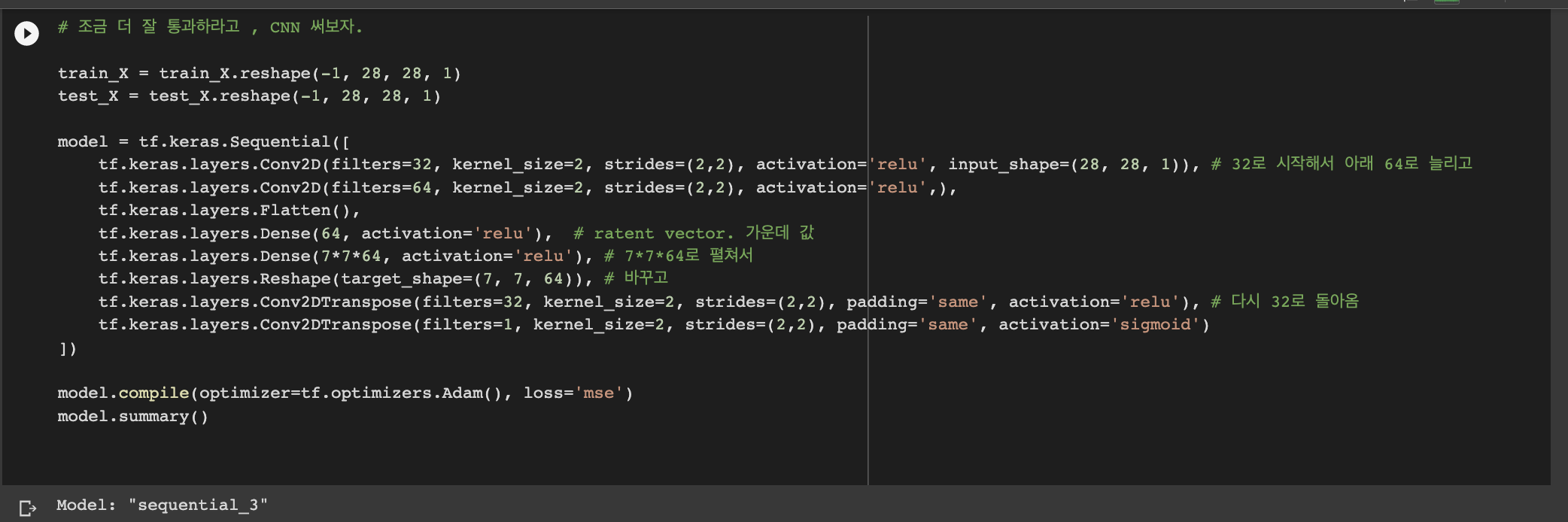
(28,28) 사이즈의 train_X가 strides=(2,2)로 인해 2칸씩 건너 측정되면서 (14,14)로 줄고, 또 통과하면서 (7,7)이 되어 reshape의 (7, 7, 64)가 구성되는 것이다. Conv2d의 filters=32가 Conv2DTranspose의 filters=32 / Conv2D의 필터 64가 Dense, reshape의 64로 연결된다.
다시 fit 시키고 결과를 봤을 때, 화질이 조금은 계선된 것으로 보이나 차이가 너무 미묘하다.
그래서, ReLU 말고 ELU를 사용해보았다. 맨 마지막의 sigmoid를 뺀 activation을 모두 elu로 바꿔준 뒤, 다시 fit, 결과를 그려본다.
화질이 원본과 상당히 비슷할 정도로, 개선되었다.
즉, 나비모양으로 구성되어있던 AutoEncoder의 가운데, latent vector가 완벽에 가깝게 특성을 잘 추출했다고 볼 수 있다.
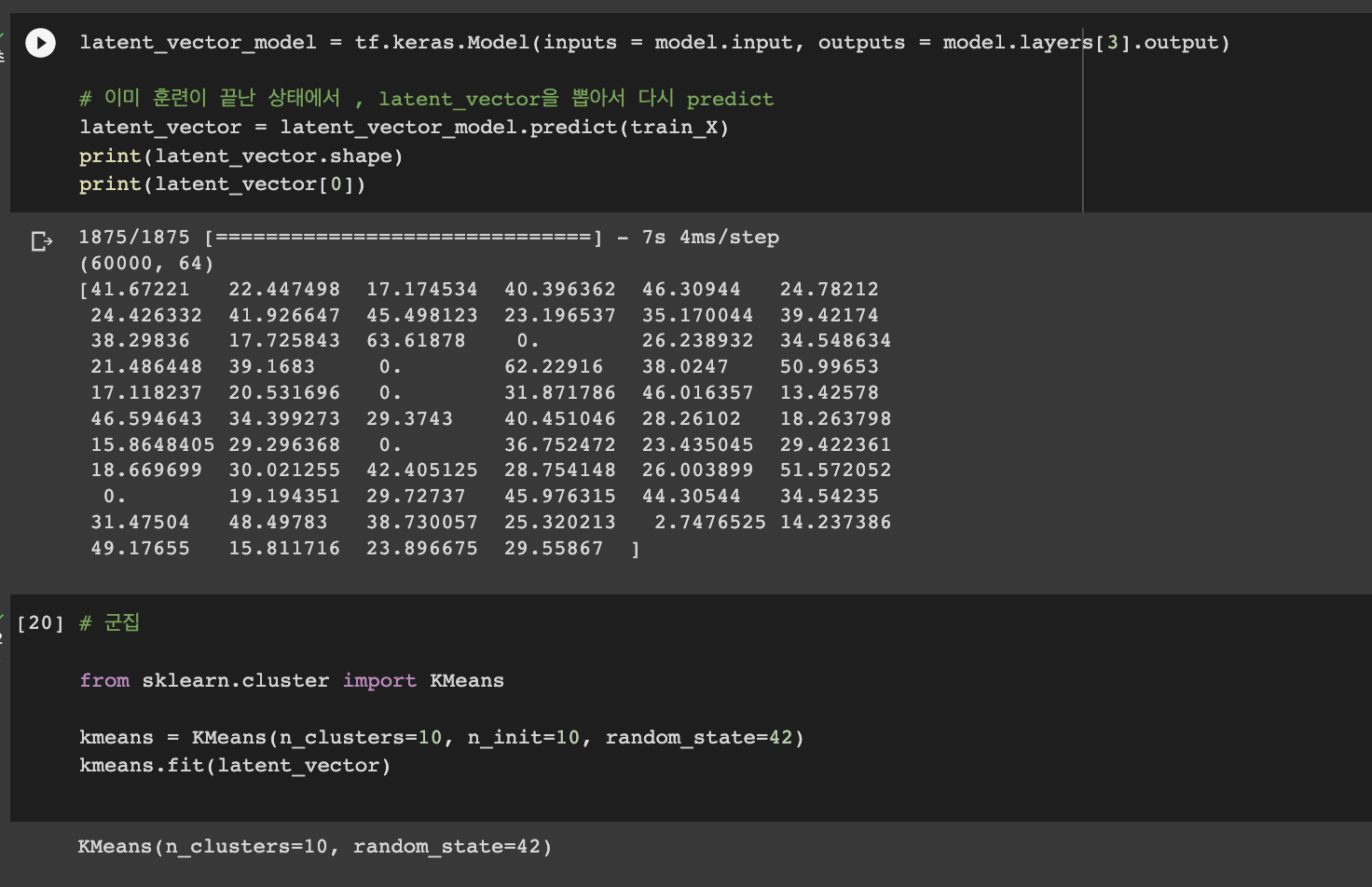
그래서, 이미 훈련이 끝난 상태에서 latent Vector을 뽑아서 다시 predict 해봤다.( KMeans 사용)

KMeans label별로 뽑았다.
6만개의 숫자를 64개의 피쳐로 뽑은 뒤, 군집화 시킨 것이다. 즉, 실제 숫자가 아니라 AutoEncoder을 이용해서 latent Vector을 뽑아낸내고, 그 latent vector를 가지고 군집화 된 이미지들인 것이다.
생각보다 잘 구분되지 않았다고 볼 수도 있지만, 각 줄을 잘 보면 숫자의 모양이 비슷한 것 같기도 하다.
판단은 보는 이의 몫이다.
'Deep Learning' 카테고리의 다른 글
| [DL] DeepLearning 이모저모 (0) | 2023.02.19 |
|---|---|
| [DL] t-SNE (0) | 2023.02.19 |
| [DL] Transfer learning _ 기본 option (0) | 2023.02.16 |
| [DL] options in DeepLearning ( Transfer learning) (0) | 2023.02.16 |
| [DL] Deep Learning Scratch (0) | 2023.02.13 |



