1. PIPELINE
- transformers는 GPT와 BERT의 핵심 모듈이다
- preprocess -> 모델 -> post process
- task마다 default model이 정해져 있다.
from transformers import pipeline
# 긍정 부정 감정 분석
classifier = pipeline('sentiment-analysis')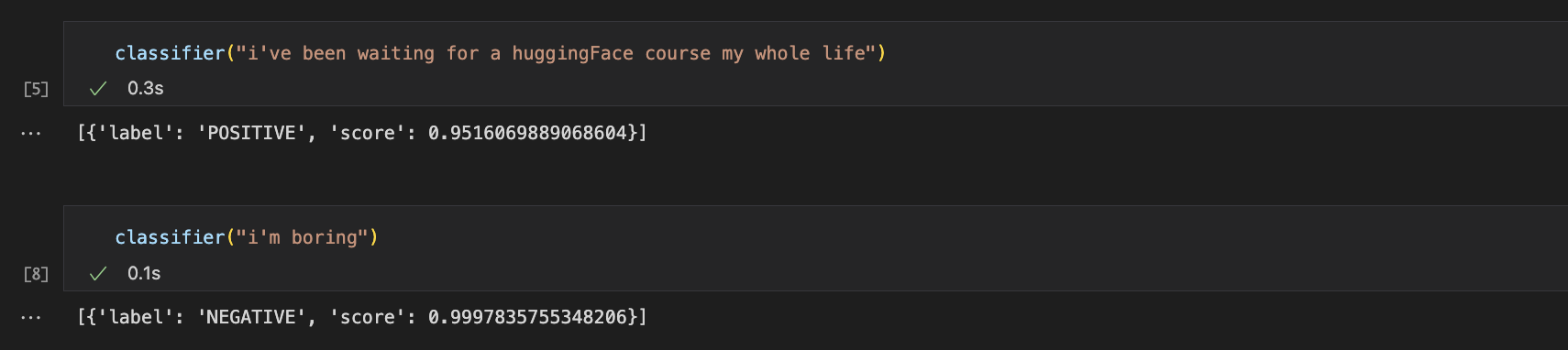
# 이 모델은 레이블이 없는 상태
classifier = pipeline('zero-shot-classification')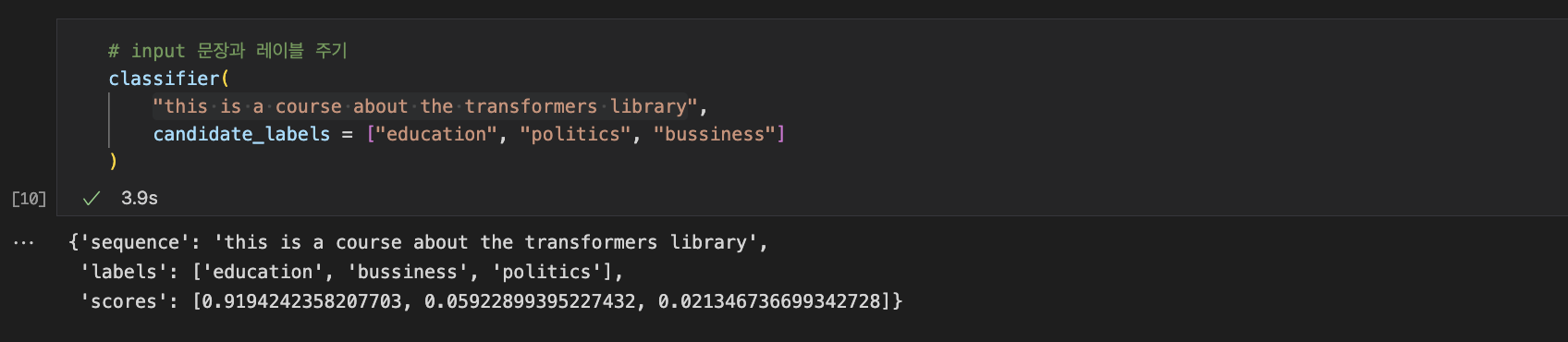
# 생성모델 , bert 기반(꽤 무겁다)
generator = pipeline('text-generation')
# num_return_sequences = 문장의 갯수 / max_length = 단어 갯수
generator("in this course, we will teach you how to", num_return_sequences =5, max_length=50)
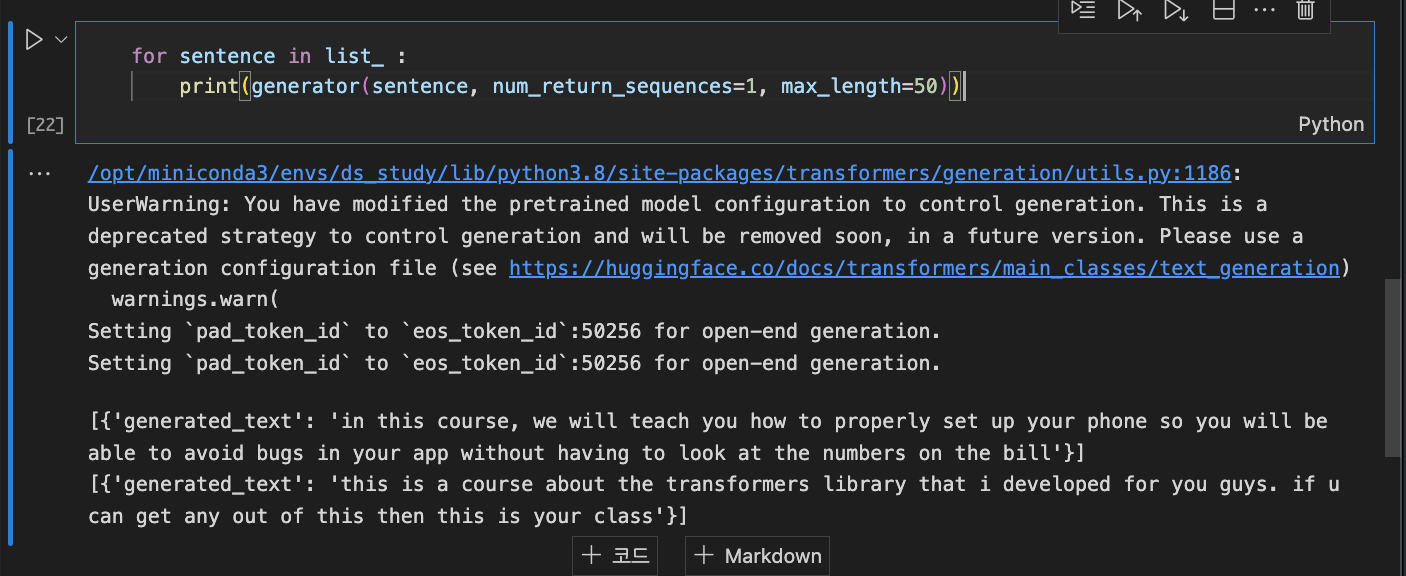
# 이런식으로 세팅도 되겠지
list_ = ["in this course, we will teach you how to", "this is a course about the transformers library"]
for sentence in list_ :
print(generator(sentence, num_return_sequences=1, max_length=50))
generator = pipeline('text-generation', model = "huggingtweets/dril")
모델은 사용하고 싶은 것으로의 특정이 가능하다.
예를 들면, pipeline()은 gpt2만 불러오게 되는데, 만약 tweeter같은 모델 쓰고 싶으면 parameter 값 수정해주면 된다.
model = ''에 들어갈 model은 huggingFace의 model 카테고리에 다 있다.
https://huggingface.co/huggingtweets/dril?text=My+dream+is
huggingtweets/dril · Hugging Face
This model can be loaded on the Inference API on-demand.
huggingface.co
1-1. MASK FILLING
- BERT나 GPT에서 가장 pretrained로 많이 쓰인다.
- 그냥 긍정 부정, text-generation은 아직 뭔가 미완성인 느낌이 강한 반면, mask filling은 결과가 꽤나 괜찮은 것 같다.
- ner이라고 ntt를 다시 arrange하는 것도 있다.
unmasker = pipeline("fill-mask")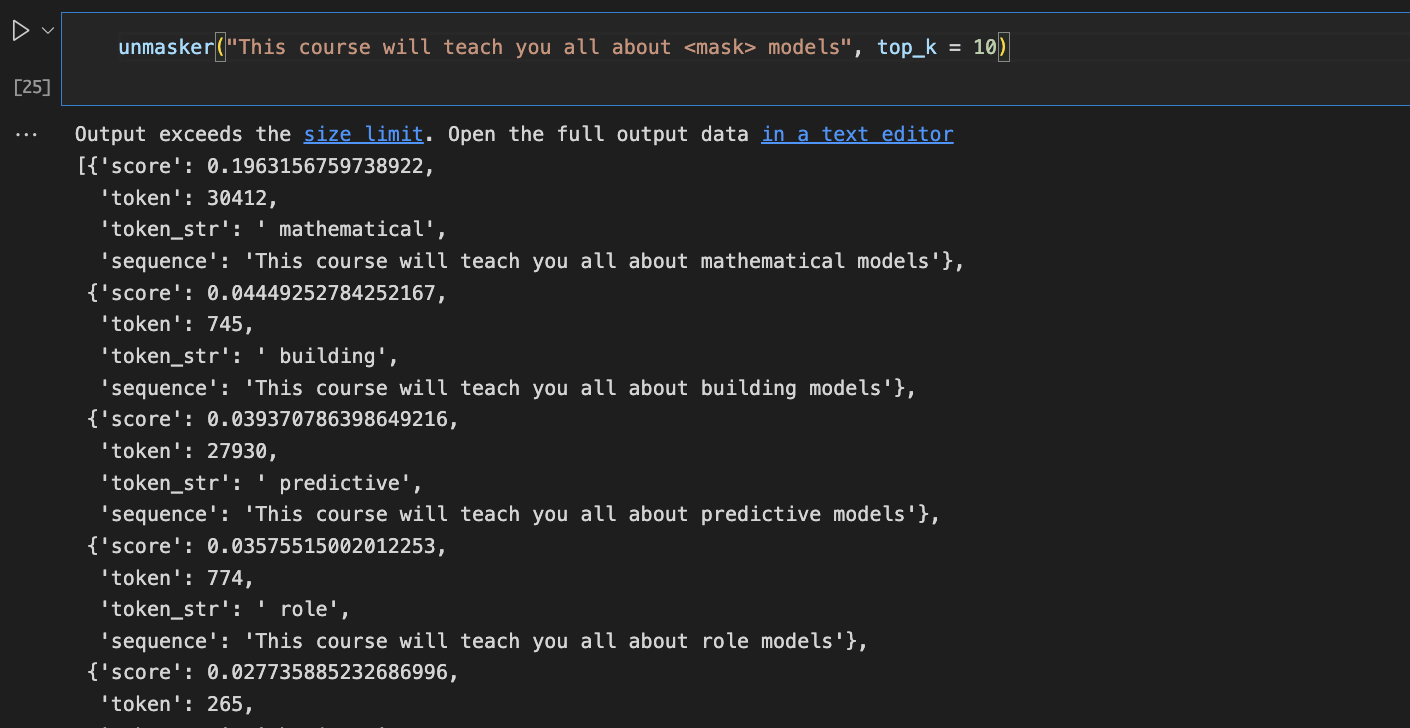
<mask>안에 들어갈 token_str을 score과 함께 보여준다.
# ner이라고 해서 ntt 다시 arrange 하는 것도 있음.
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and i work at Hugging Fase in Brooklyn.")ner을 통한 해당 코드의 출력문을 보면 entity_group 보면 per = person, Org = organigation loc = location
등 token에 대한 부가정보를 쉽게 확인 가능하다.
# question answering
question_answerer = pipeline("question-answering")
question_answering을 통해 원하는 question과 context를 입력하면
score과 해당 단어의 위치, answer을 보여준다.
summarizer = pipeline("summarization")
summarizer(
"the lonng g ------- story shoud be here !"
)summarizer을 통한 input text의 간략화도 가능하다.
# 번역
translator = pipeline("translation", model = "Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face")translation. model은 huggingFace에서 french -> english로 번역해주는 것을 가져왔다.